class: middle, left, inverse, title-slide .title[ # Описательная статистика ] .subtitle[ ## Основы биостатистики, осень 2022 ] .author[ ### Марина Варфоломеева ] --- ## Описательная статистика - Описательная статистика: меры центральной тенденции и разброса - Мода - Медиана - Связка среднее арифметическое и стандартное отклонение - Медиана и межквартильное расстояние - Коэффициент вариации - Боксплоты - Сопоставление свойств средней и медианы, стандартного отклонения и межквартильного расстояния - Накопленные частоты и пропорции: квантили и перцентили, кумулята и огива, пропорции --- class: middle, center, inverse # Описательная статистика: <br/>меры центральной тенденции и разброса --- ## Пример: длина ящериц Допустим, вы поймали несколько ящериц и измерили их длину (см). .pull-left[  .tiny[<a href="https://commons.wikimedia.org/wiki/File:Viviparous_lizard_(Zootoca_vivipara)_in_the_Aamsveen,_The_Netherlands.jpg">Ocrdu</a>, <a href="https://creativecommons.org/licenses/by-sa/4.0">CC BY-SA 4.0</a>, via Wikimedia Commons] ] .pull-right[  10, 4, 7, 8, 7, 6, 11, 6, 13, 6, 10 ] ??? Представьте, что у нас есть такой датасет. Было бы удобнее описать его парой чисел и не приводить все исходные данные. Кроме того, сжатое описание данных — это способ лучше в них разобраться. --- ## Ряд наблюдений можно изобразить <br/>на гистограмме __Гистограмма__ — способ изображения частотных распределений. По оси Y отложена __частота__ (или доля, процент) наблюдений, попадающих в определенный диапазон (__классовый интервал__). .pull-left[  10, 4, 7, 8, 7, 6, 11, 6, 13, 6, 10 ] .pull-right[ <!-- --> ] Классовые интервалы от 3.5 до 4.5, от 4.5 до 5.5, от 5.5 до 6.5 и т.п. --- ## Задание 1 Мониторинг качества работы гинекологов в 1991-1995 гг. в двух регионах Англии (Harley et al., 2005). Один из исследованных параметов — распределение частоты женщин в возрасте до 25 лет, которым была проведена стерилизация. .pull-left-40[ - Что это за график? - Что измеряет ось Y? - Какие подозрительные вещи видны на этом графике? Как можно кратко описать эти данные, чтобы не приводить весь ряд? ] .pull-right-60[  ] ??? Отскок справа — это Rodney Ledward, недобросовестный гинеколог, который был отстранен от работы (еще ранье и в другом месте). Рис. исходно из [doi:10.1136/bmj.38377.675440.8F](https://doi.org/10.1136/bmj.38377.675440.8F) --- ## Описательная статистика Описательная статистика служит для краткого количественного описания данных. .pull-left[ - __Меры центральной тенденции__ <br/>(_measures of location_) ] .pull-right[ - __Меры разброса__ <br/>(_measures of spread_) ] --- ## Меры центральной тенденции <br/>(_measures of location_) Оценивают, где расположены данные .pull-left-40[ - мода - медиана - среднее арифметическое, геометрическое и т.п. ] .pull-right-60[  .tiny[by geojango_maps at Unsplash] ] ??? График из примера, отметить разные --- ## Меры разброса, показатели вариации, <br/>(_measures of spread_) Описывают изменчивость, ширину распределения данных .pull-left-40[ - размах, диапазон варьирования - дисперсия - стандартное отклонение - коэффициент вариации - квантили, перцентили ] .pull-right-60[  .tiny[Картина "сеятель, разбрасывающий облигации государственного займа" из к.ф. "12 стульев"] ] ??? График из примера, отметить разные. Картина "сеятель, разбрасывающий облигации государственного займа". --- ## Традиционные связки статистик Мера центральной тенденции обычно используется вместе с подходящей мерой разброса. - медиана и квантили - среднее и стандартное отклонение ??? Некоторые связки статистик традиционно используются вместе: мера центральной тенденции и подходящая для неё мера разброса. Например,… Для моды нет традиционного компаньона. Для начала мы разберемся с мерами центральной тенденции, а потом посмотрим на связки статистик центральной тенденции и разброса. Максимально сжатое описание данных — это представить их в виде одного единственного числа, отображающего их самое характерное, "центральное" значение. Но что такое "характерное/типичное/центральное" будет зависеть от определения этих понятий. Разные описательные статистики будут высвечивать разные особенности данных. Т.е. чтобы выбрать правильную меру центральной тенденции, нужно представлять, что именно вы хотите показать. --- class: middle, center, inverse background-image: url("img/mode-umbrellas-unsplash.png") background-position: center background-size: cover # Мода .tiny[by smile_97 at Unsplash] --- ## Мода __Мода__ — наиболее часто встречающееся значение в наборе данных. <br/> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13  --- ## Мода Мода — наиболее часто встречающееся значение в наборе данных. <br/> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 Мода равна 6 .pull-left[ <table> <thead> <tr> <th style="text-align:left;"> значение </th> <th style="text-align:right;"> частота </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> 4 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> 6 </td> <td style="text-align:right;"> 3 </td> </tr> <tr> <td style="text-align:left;"> 7 </td> <td style="text-align:right;"> 2 </td> </tr> <tr> <td style="text-align:left;"> 8 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> 10 </td> <td style="text-align:right;"> 2 </td> </tr> <tr> <td style="text-align:left;"> 11 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> 13 </td> <td style="text-align:right;"> 1 </td> </tr> </tbody> </table> ] .pull-right[ <!-- --> ] ??? --- ## Мода часто используется для категориальных данных <!-- --> ??? Для категориальных данных бывает интересно узнать, какая категория встречается чаще всего. Например, здесь это … --- ## Мода может быть не одна <!-- --> ??? Поскольку в данных может быть несколько частых значений, мода не очень удачна для описания центральной тенденции. Здесь на картинке две моды с одинаковой частотой. Какая из них лучше описывает данные? ## Может не быть моды вообще <!-- --> ??? Или представьте, что вы измеряете рост 15 человек с точностью до 1 мм. Как будет выглядеть распределение веса? Вы вряд ли получите совпадающие значения, значит никакой моды не будет (если не объединять наблюдения в группы). (если больше людей, то будут повторы) ## Мода может быть не в центре распределения <!-- --> ??? В некоторых случаях мода не дает представления о положении центральной тенденции, т.к. может быть не в "центре" распределения, а "с краю". --- ## Унимодальные и бимодальные распределения — термины, позволяющие различать распределения с разным количеством вершин <!-- --> ??? Тем не менее, благодаря моде у нас появляются термины для распределений с разным количеством вершин. --- class: middle, center, inverse background-image: url("img/boats-median-unsplash.png") background-position: center background-size: cover # Медиана .tiny[by benharritt at Unsplash] --- ## Медиана __Медиана__ — это число, которое делит пополам упорядоченный ряд наблюдений. Чтобы ее найти, нужно отсортировать (ранжировать) наблюдения.  Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 ??? --- ## Медиана Если нечетное число наблюдений, то его середина — это медиана.  Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, медиана 7 -- Если четное число наблюдений, то медиана находится между двумя центральными (их среднее арифметическое).  Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, 20, медиана 7.5 ??? --- ## Медиана <!-- --> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, медиана 7 --- class: middle, center, inverse ## Среднее значение --- ## Разнообразие средних значений Обычно под термином __среднее значение__ мы подразумеваем __среднее арифметическое__. Но есть и другие варианты средних значений: - среднее квадратическое, - среднее кубическое, - среднее гармоническое, - среднее геометрическое. (О них в дополнительной презентации). --- ## Среднее арифметическое `$$\bar{x}=\frac{x_{1}+x_{2}+\cdots+x_{n}}{n}=\frac{\sum x_{i}}{n}$$` Среднее в выборке обозначается `\(\bar{x}\)`, а в генеральной совокупности μ --- class: middle, center, inverse # Связка среднее арифметическое и стандартное отклонение ??? Статистики для описания выборок всегда ходят парами. Меры центральной тенденции всегда используются вместе с мерами разброса. Сейчас мы рассмотрим одну такую связку, пожалуй, самую популярную. --- ## Среднее значение `$$\bar{x}=\frac{\sum{x_i}}{n}$$` <!-- --> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, среднее значение `\(\bar{x}=8\)` -- ### Как оценить разброс значений вокруг среднего? --- ## Подойдет ли девиата для оценки разброса? __Девиата__ (отклонение) — это разность между значением вариаты (измерения) и средним: `$$x_i - \bar{x}$$` 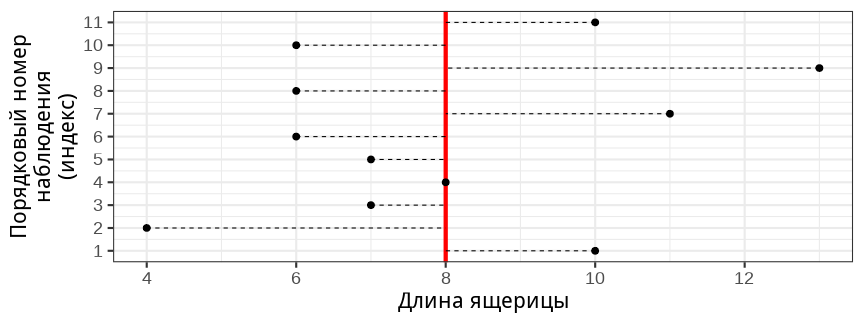<!-- --> Данные 10, 4, 7, 8, 7, 6, 11, 6, 13, 6, 10, среднее значение `\(\bar{x}= 8\)` Девиаты 2, -4, -1, 0, -1, -2, 3, -2, 5, -2, 2 --- ## Девиаты не годятся как мера разброса Нельзя так просто сложить все значения девиат и поделить их на объем выборки. __Сумма девиат всегда будет равна нулю__. -- .pull-left-45[ `$$\begin{aligned} \sum{(x_i - \bar{x})} &= \sum x_i - \sum \bar x = \\ &= \sum x_i - n \bar x = \\ &= \sum x_i - n \cfrac{\sum x_i}{n} = 0 \end{aligned}$$` ] -- .pull-right-55[ Девиаты 2, -4, -1, 0, -1, -2, 3, -2, 5, -2, 2 Сумма девиат 0 ] ??? Мем из властелина колец про нельзя так просто --- ## Сумма квадратов (SS, Sum of Squares) Чтобы избавиться от знака, возведем девиаты в квадрат __Сумма квадратов отклонений__: `$$SS = \sum{{(x_i - \bar{x})}^2} \ne 0$$` <!-- --> Девиаты 2, -4, -1, 0, -1, -2, 3, -2, 5, -2, 2 -- Сумма квадратов отклонений (девиат) `\(SS = 72\)` -- Но на что разделить `\(SS\)`, чтобы получить __усредненное__ отклонение от `\(\bar{x}\)`? --- ## Как усреднить отклонения от среднего значения? Мы не можем делить на `\(n\)`, поскольку __в выборке__ отклонения от среднего `\(x_i - \bar x\)` не будут независимы: Что это значит? Сумма отклонений всегда равна нулю `\(\sum{(x_i - \bar{x})} = 0\)`. Поэтому, если мы знаем `\(\bar x\)` и `\(n - 1\)` отклонений, то всегда сможем точно вычислить последнее отклонение. <br /> `\(n - 1\)` — это число независимых значений (__число степеней свободы__, __degrees of freedom__). --- ## Дисперсия (MS, Mean Square, Variance) Если мы поделим сумму квадратов на объем выборки минус 1, то получим дисперсию для этой выборки. `$$s^2=\frac{\sum{(x_i - \bar{x})^2}}{n - 1}= \frac{SS}{n - 1}$$` __Дисперсия__ (средний квадрат отклонений) — характеристика разброса. - `\(s^2\)` — дисперсия в выборке - `\(\sigma^2\)` — дисперсия в генеральной совокупности -- <br/> В нашем примере дисперсия `\(s^2 = \frac{72}{11 - 1} = 7.2\)` <br/> Дисперсию нельзя изобразить на графике, т.к. там используются не отклонения, а их квадраты. --- ## Среднеквадратичное/стандартное отклонение = Standard Deviation Квадратный корень из дисперсии позволит вернуться к исходным единицам измерения. `$$s = \sqrt{s^2} = \sqrt{\frac{\sum{(x_i - \bar{x})^2}}{n - 1}} = SD$$` __Стандартное (среднеквадратичное) отклонение__ — характеристика разброса (усредненное отклонение от среднего). - `\(s\)` — стандартное отклонение в выборке - `\(\sigma\)` — стандартное отклонение в генеральной совокупности -- <br/> Стандартное отклонение `\(s = \sqrt{\frac{72}{11 - 1}} = \sqrt{ 7.2 } = 2.68\)` Стандартное отклонение — это средняя величина отклонения, и ее уже можно изобразить на графике. --- ## Среднее и стандартное отклонение на графиках .pull-left[ Для наглядности посмотрим на них на гистограмме. <!-- --> ] -- .pull-right[ Но чаще их изображают в виде точки с усами. <!-- --> ] -- __Внимательно читайте подписи__ к графикам, т.к. усы могут означать: - 1 или 2 стандартных отклонения (SD) - стандартную ошибку среднего (SE, см. далее) - доверительный интервал к среднему значению - диапазон значений (минимум, максимум) ??? При вычислении не округляют промежуточные результаты. Конечный результат описательных статистик часто округляют, оставляя на один разряд больше, чем исходные величины [@whitlock2015AnalysisBiologicalData, p.70]. --- ## Коэффициент вариации __Коэффициент вариации__ — это стандартное отклонение, выраженное в процентах относительно среднего значения признака. `$$CV=\frac{s}{\bar{x}} \times 100 \%$$` Чем больше коэффициент вариации, тем сильнее выражена изменчивость признака. -- .pull-left[     `\(\bar x = 7\)` см, `\(s = 5\)` см `\(CV = 71.43 \%\)` ] -- .pull-right[     `\(\bar x = 8\)` м, `\(s = 1\)` м `\(CV = 12.5 \%\)` ] ??? = относительное стандартное отклонение Земляные червяки, среднее 7 см, стандартное отклонение 5 см. Удавы, среднее 8 м, стандартное отклонение 96 см. Кто из них имеет более изменчивый размер тела? Величина стандартного отклонения здесь сама по себе не поможет. Нам нужно использовать какую-то относительную шкалу изменений, которая бы учитывала величину самого признака. Пусть средний размер земляных червяков 7 см, тогда стандартное отклонение 5 см — это очень много. CV 71,43 %. В то же время, при среднем размере удавов 8 м, тогда стандартное отклонение 96 см — это очень мало. CV = 12% CV используется только для признаков со значениями больше нуля. Коэффициент вариации используется для сравнения изменчивости признаков, выраженных в разных шкалах. Приведенная выше формула — это смещенная оценка. Несмещенная для нормально-распределенных данных `\({\widehat{c_{\mathrm{v}}}}^{*}=\left(1+\frac{1}{4 n}\right) \widehat{c_{\mathrm{V}}}\)` --- class: middle, center, inverse # Связка медиана и межквартильное расстояние --- ## Медиана Медиана — это число, которое делит пополам упорядоченный ряд наблюдений. Справа и слева от медианы находятся по 50% наблюдений. <br/><br/><br/><br/><br/> .pull-left[ <!-- --> ] .pull-right[ Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, медиана 7 ] --- ## Квартили Квартили делят распределение на __четыре__ равные части, каждая из которых включает по 25% значений. - I квартиль отсекает первые 25%. - II квартиль (медиана) — 50%. - III квартиль отсекает 75% значений. <br/> .pull-left[ <!-- --> ] .pull-right[ Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, медиана 7 Квартили: ``` 25% 50% 75% 6 7 10 ``` ] --- ## 5-number summary __5-number summary__ — минимум, квартили, максимум — удобное краткое описание данных. <br/><br/><br/><br/><br/> .pull-left[ <!-- --> ] .pull-right[ Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13, медиана 7 5-number summary: ``` 0% 25% 50% 75% 100% 4 6 7 10 13 ``` ] --- ## Боксплот: 5-number summary на графике .pull-left[ 5-number summary: ``` 0% 25% 50% 75% 100% 4 6 7 10 13 ``` <!-- --> ] .pull-right[ По оси Y отложены характеристики выборки: - жирная линия — медиана, - нижняя и верхняя границы "коробки" — это I и III квантили, - усы — минимум и максимум. __Интерквартильное расстояние__ — расстояние между I и III квартилями (высота "коробки") Если в выборке есть выбросы (значения, отстоящие от границ "коробки" больше чем на 1.5 интерквартильных расстояния), то они будут изображены отдельными точками. ] --- ## Задание 2 Распределение массы тела млекопитающих (в граммах, log-трансформация) (Smith et al. 2003). .pull-left-45[ - Что это за график? - Что значит горизонтальная линия в центре коробки и границы коробки? - Что означают горизонтальные черточки вверху и внизу первой и второй коробок? ] .pull-right-55[  ] - Сравните положение распределений размера тела. - Какие из них относительно симметричны / асимметричны? Почему вы так решили? - В какой из групп наименьший разброс значений? - Как могли повлиять вымирания видов в ледниковый период и в наше время на распределение размеров млекопитающих? ??? TODO: Whitlock and Schluter 2015, p.86, ex.4 --- class: middle, center, inverse # Сопоставляем свойства ## среднего и медианы, ## стандартного отклонения и межквартильного расстояния --- ## Медиана и среднее Медиана отделяет 50% данных.  <br/> Среднее "уравновешивает" данные.  --- ## Среднее плохо работает для асимметричных распределений  --- ## Среднее неустойчиво к выбросам __Выбросы__ (outliers) — наблюдения сильно отличающиеся от большинства   -- Стандартное отклонение еще более неустойчиво, т.к. расчитывается исходя из __квадратов__ отклонений. --- ## Задание 3 Распределение числа слов, произнесенных в течение 17 часового дня людьми (n = 396) (Mehl et al. 2017). Мужчины в среднем произносили 15 669 слов (n = 186), а женщины 16 215 слов (n = 210). .pull-left[  ] .pull-right[ - Что это за график? - Какая переменная из использованных на графике является откликом, а какая предиктором? - Чему равна мода каждого из распределений? - Медианное число произносимых слов в день выше у мужчин или женщин? - У какого из полов скорее всего выше дисперсия числа произносимых слов в день? ] ??? TODO: Whitlock and Schluter 2015, p.86, ex.5 --- ## Когда использовать какую из статистик? - Категориальные данные — мода. - Ранговые данные — медиана. - Численные данные (симметричные, без выбросов) — среднее. Но можно и медиану, если что. - Численные данные (несимметричные, могут содержать выбросы) — медиана. --- class: middle, center, inverse # Накопленные частоты и пропорции --- ## Квантили __Квантили__ делят ряд наблюдений на равные части. .pull-left[ <!-- --> ] .pull-right[ Квантили называются по-разному в зависимости от числа частей. Примеры квантилей: - 2-квантиль ("два-квантиль") — медиана - 4-квантиль ("четыре-квантиль")--- квартиль - 100-квантиль ("сто-квантиль")--- перцентиль ] --- ## Перцентили __Перцентиль__ — частный случай квантиля. Всего 99 перцентилей, они делят ряд наблюдений на 100 частей. <br/> .pull-left[ Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 <br/> Какие значения отсекают 10% или 99% значений выборки? 10-й и 99-й перцентили: ``` 10% 99% 6.0 12.8 ``` ] .pull-right[ <!-- --> ] --- ## Квантили и перцентили .pull-left[ <!-- --> ] .pull-right[ Квантиль показывает __какая часть__ данных меньше или равна ему: - 1-квартиль — ¼ часть - 2-квартиль — ½ часть - 3-квартиль — ¾ части Перцентиль показывает __какой процент__ данных меньше или равен ему: - 1й перцентиль — 1% - 2й перцентиль — 2% - … - 99й перцентиль — 99% ] -- А что если нарисовать на графике эти перцентили последовательно? --- ## Кумулятивное частотное распределение __Кумулятивное частотное распределение__ показывает, какая доля значений наблюдений меньше или равна определенному значению по оси х. -- <br/> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 .pull-left[ <!-- --> ] -- .pull-right[ <table> <thead> <tr> <th style="text-align:right;"> Значение </th> <th style="text-align:right;"> Накопленная частота </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 0.091 </td> </tr> <tr> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 0.364 </td> </tr> <tr> <td style="text-align:right;"> 7 </td> <td style="text-align:right;"> 0.545 </td> </tr> <tr> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0.636 </td> </tr> <tr> <td style="text-align:right;"> 10 </td> <td style="text-align:right;"> 0.818 </td> </tr> <tr> <td style="text-align:right;"> 11 </td> <td style="text-align:right;"> 0.909 </td> </tr> <tr> <td style="text-align:right;"> 13 </td> <td style="text-align:right;"> 1.000 </td> </tr> </tbody> </table> ] --- ## Читаем кумуляту <br/><br/><br/> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 .pull-left[ <!-- --> ] .pull-right[ <table> <thead> <tr> <th style="text-align:right;"> Значение </th> <th style="text-align:right;"> Накопленная частота </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 0.091 </td> </tr> <tr> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 0.364 </td> </tr> <tr> <td style="text-align:right;"> 7 </td> <td style="text-align:right;"> 0.545 </td> </tr> <tr> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0.636 </td> </tr> <tr> <td style="text-align:right;"> 10 </td> <td style="text-align:right;"> 0.818 </td> </tr> <tr> <td style="text-align:right;"> 11 </td> <td style="text-align:right;"> 0.909 </td> </tr> <tr> <td style="text-align:right;"> 13 </td> <td style="text-align:right;"> 1.000 </td> </tr> </tbody> </table> ] --- ## Огива Если "перевернуть" кумуляту, получится __огива__. <br/><br/><br/> Данные 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 .pull-left[ <!-- --> ] .pull-right[ <table> <thead> <tr> <th style="text-align:right;"> Значение </th> <th style="text-align:right;"> Накопленная частота </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 0.091 </td> </tr> <tr> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 0.364 </td> </tr> <tr> <td style="text-align:right;"> 7 </td> <td style="text-align:right;"> 0.545 </td> </tr> <tr> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 0.636 </td> </tr> <tr> <td style="text-align:right;"> 10 </td> <td style="text-align:right;"> 0.818 </td> </tr> <tr> <td style="text-align:right;"> 11 </td> <td style="text-align:right;"> 0.909 </td> </tr> <tr> <td style="text-align:right;"> 13 </td> <td style="text-align:right;"> 1.000 </td> </tr> </tbody> </table> ] --- ## Пропорции (= доли) __Пропорция__ (доля) — часть наблюдений от общего их количества. `$$p = \frac{n_i}{n}$$` - `\(n_i\)` — число наблюдений в определенной категории - `\(n\)` — общее количество наблюдений --- ## Пропорции и среднее значение У долей и среднего значения много общего. -- <br/> Данные: 4, 6, 6, 6, 7, 7, 8, 10, 10, 11, 13 Какая доля ящериц длиной меньше 8 см? -- Можно заменить измерения на 1, если ящерица < 8 см, и на 0, если больше. 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0 -- Тогда доля ящериц меньше 8 см будет `\(p = \frac{\sum{x_i}}{n} = \frac{6}{11} = 0.545\)` -- Формула напоминает среднее значение. --- ## Задание 4 Темпы роста населения в 204 странах (United Nations Statistics Division 2004), выраженные как средний годовой процент изменения суммарной численности населения в период с 2000 по 2004 гг. .pull-left-60[  ] .pull-right-40[ - Что это за график? - Что за величина отложена по оси Y? ] - Каков приблизительный процент стран, где численность населения уменьшается? - Определите на глаз: - медианное значение темпов роста населения - 90 перцентиль изменения численности населения ??? TODO: Whitlock and Schluter 2015, p.86, ex.10 --- class: middle, center, inverse # Summary --- ## Summary ### Описательные статистики Меры центральной тенденции - Мода — наиболее часто встречающееся значение в ряду данных. - Медиана — делит пополам упорядоченный ряд наблюдений. - Среднее значение — обычно под ним подразумевается среднее арифметическое. Но есть и другие варианты средних значений: среднее квадратическое, кубическое, гармоническое, геометрическое. -- Меры разброса - Квантили — числа, которые делят ряд наблюдений на определенное число частей (например, квартили — на 4, перцентили — на 100). - Девиата — отклонение значения от среднего. - Дисперсия — средний квадрат отклонений. - Среднеквадратичное (стандартное) отклонение — квадратный корень из дисперсии. - Коэффициент вариации — стандартное отклонение, выраженное в процентах от среднего значения. --- ## Summary ### Связки описательных статистик - Среднее арифметическое и стандартное отклонение лучше использовать когда распределение данных относительно симметрично и не содержит выбросов. - Медиана и межквартильное расстояние лучше, чем среднее значение, работают с несимметричными распределениями, при наличии выбросов или для ранговых данных. --- ## Summary ### Изображение описательных статистик - Гистограмма — способ изображения частотных распределений. По оси Y отложена частота или процент наблюдений, попадающих в определенный диапазон. - Боксплоты — способ графического изображения 5-number summary: минимум, I квартиль, медиана, III квартили, максимум. - Кумулята и огива — это способы изобразить накопленные частоты и пропорции. --- ## Что почитать - Sokal, R.R., Rohlf, F.J., 1995. Biometry (3rd edn). WH Freeman and company: New York. - Zar, J.H., 2010. Biostatistical Analysis. Prentice Hall: New York.